



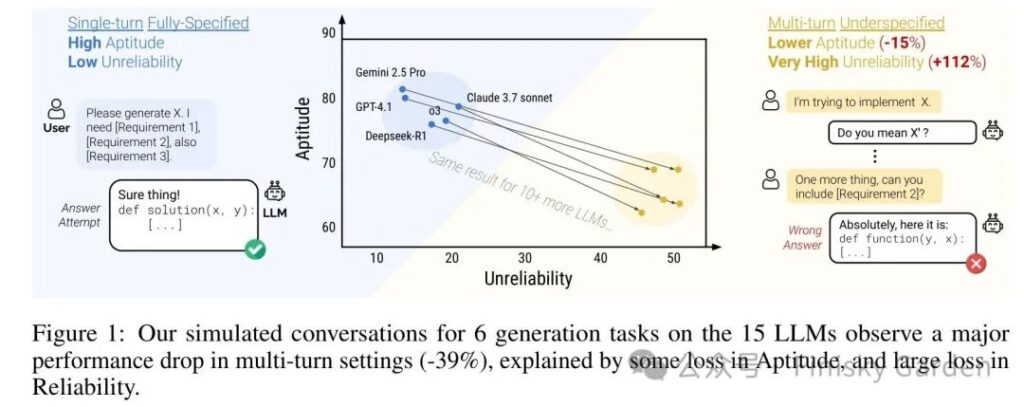
跟 ChatGPT 多聊几轮、边聊边补需求,是不是常常感觉它越聊越走偏?这不是你的错觉。ICLR 2026 这篇杰出论文用 20 万次模拟对话给出了答案:15 个主流 LLM 在多轮对话中平均掉 39%,Gemini 2.5 Pro、GPT-4.1、Claude 3.7 Sonnet、o3全都中招。
论文来自 Microsoft Research 与 Salesforce Research 的合作研究,标题非常直白:LLMs Get Lost In Multi-Turn Conversation。
论文特别强调 unreliability 的增加在所有模型上水平接近,跟模型规模、是否带 reasoning、是否闭源无关。换句话说,模型多轮场景下不是变笨了,是变得不稳定,同一个任务跑十次,最好和最差结果差出 50 个百分点。模型能力(aptitude)只下降 15%,不可靠性(unreliability)却暴涨 112%。
单轮 benchmark 的局限
现在的 LLM 评测几乎都是单轮:把完整 instruction 一次性喂进去,让模型一次性输出答案。MMLU、HumanEval、GSM8K、MT-Bench 全是这套。
但实际用户不这么用。用户聊天日志表明,underspecification 是真实交互的常态:用户先抛半句话试探,再根据模型反应补充细节。这种情况下,模型必须把分散在多轮的线索拼起来才能解题。
因此,论文提出的核心问题是:把同一个完整 instruction 拆成几”份”信息(shard),每轮揭一份,模型 single-turn 时的能力还能保住吗?
sharded simulation 的实验设计
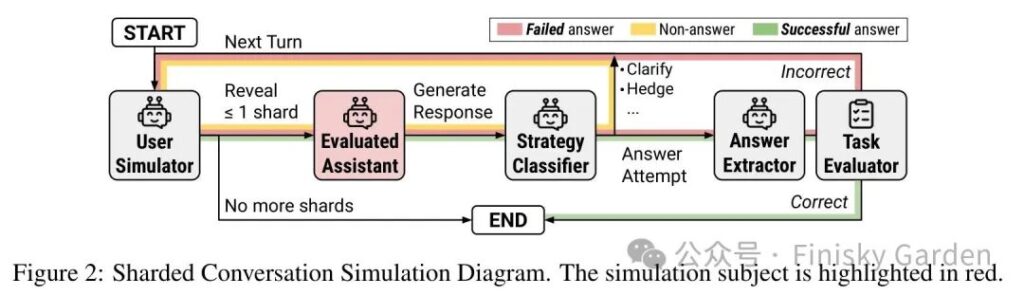
最关键的设计难点不是”怎么模拟用户”,而是”怎么让单轮和多轮的分数能直接比”。以往多轮 benchmark 都是 episodic 的,每一轮自己是个独立子任务,掉了多少没法归因。作者的做法只改一件事:保留同一个原始 instruction 不变,只改变信息揭示的方式。
围绕这个核心拉出三种设置:FULL 一次性给完整 instruction,是单轮上限;SHARDED 切成若干 shard 逐轮揭示,是真实多轮;CONCAT 把所有 shard 一次性拼成 bullet list 喂进去,作为对照组排除”sharding 本身丢信息”的解释。三者共享同一份任务和同一个 evaluator,FULL 与 SHARDED 之间的差距才能干净归因到”underspecified 多轮”这一个变量。
pipeline 四步:
- Sharding
半自动把 HumanEval、LiveCodeBench、Spider、GSM8K、ToTTo、BFCL、Summary of a Haystack 拆成原子信息单元。CONCAT 验证 sharding 没丢信息,得分与 FULL 平均相差不超过 5%。 - 三个 LLM 角色
assistant 是被测模型;user 由 GPT-4o-mini 扮演,握着完整 instruction 决定下一轮揭哪个 shard;system 给每轮回复打标签并对 answer attempt 抽取打分。被测 assistant 不知道自己在跟模拟器对话,也不知道对话会是 underspecified。 - 每轮严格 ≤ 1 shard
硬约束,模型必须等下一轮才能拿下一份信息。 - Scoring
对话最终分数取所有 answer attempt 中最高那个。这其实给了 SHARDED”红利”,单轮只能猜一次,多轮可以猜 N 次。即便如此,SHARDED 仍显著低于 FULL。
举个例子更容易理解,下图把六个任务的”原始 instruction”和对应”sharded instruction”并排放在一起:

以 Math 列(GSM8K)为例。FULL 设置下原题:
Josh 想倒卖一套房。他花 $80k 买入,又花了 $50k 装修,房价涨了 150%。他赚了多少?
sharding 之后变成 5 个 shard,模拟器一轮揭一个:先说”我朋友 Josh 卖房了,想知道赚了多少”,再依次补”买入 $80,000″”装修花了 $50k””房价涨了 150%”,最后追一句”就这些信息,利润是多少”。
assistant 在轮 1 看到的只是”想算 Josh 卖房赚了多少”,连买入价都没有。论文观察到:多数模型在轮 1 就给一个完整 answer attempt(”假设买入价是 X、装修花了 Y,利润是 Z”),把后面三轮的信息全靠 assumption 补上。后续 shard 真正揭出来后,模型不会推翻第一轮的框架,而是基于错误前提反复打补丁。即使最终分数取所有 attempt 中最高那个,多轮还是显著输给单轮。
15 个模型 × 6 个任务 × 每组 N=10 次重复,共 20 万+ 对话,成本约 5000 美元。
性能下降的程度
每个模型在每个任务上都掉,平均 -39%。
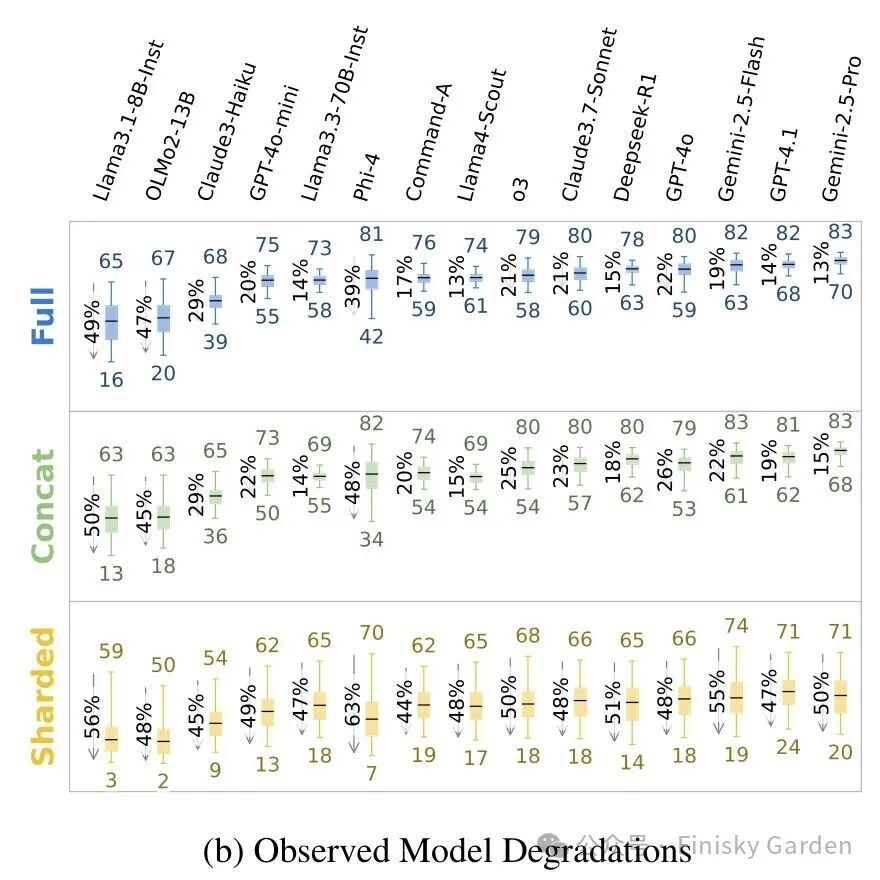
CONCAT(一次性拼起来)的得分与 FULL 持平(95%),排除了”sharding 丢了信息”或”rephrase 影响理解”的解释。性能下降是 multi-turn underspecified 这个结构带来的。
强模型并没有更扛。看上面箱线图,Gemini 2.5 Pro、GPT-4.1、Claude 3.7 Sonnet 这些 FULL 平均分在 80 上下的模型,到 SHARDED 普遍掉到 65-75,与 Llama3.1-8B 的 59 差距比 FULL 时小得多。
加 test-time compute 也救不回来。o3 和 DeepSeek-R1 掉得跟非 reasoning 模型一样,甚至更厉害,reasoning 模型回答平均长 33%,更长的回复夹带更多 assumption,反而成了负担。
迷路的四个根因
论文给出四个根因:
过早回答。SHARDED 下多数模型在第一个 shard 时就尝试给完整答案。前 20% 出现首次 attempt 的对话平均得 30.9,等到 80%-100% 才首次 attempt 的得 64.4(仅基于 Code 和 Math,其他任务模型几乎都是第一轮抢答,无法分桶)。
Answer bloat。对话越往后,answer attempt 越长。Code 任务里仅看正确解子集,FULL 平均 668 字符,SHARDED 平均 850 字符(多约 27%)。模型基于不全信息生成的早期 answer,后续即使被 invalidate 也不会真正抛弃,而是不断打补丁。最后的”正确答案”通常是缝合怪。
Loss-of-middle-turns。在 summary 任务里,第 1 轮和最后 1 轮的文档被引用最多,中间几轮的文档被严重忽略。这与 Liu et al. “Lost in the Middle” 在长文本里观察到的 attention U 形分布同源,但发生在 turn 维度。
回复啰嗦。SHARDED 回复比 FULL 长 20-300%,长出来的是模型自己脑补的 assumption。这些 assumption 一旦成文,就成了后续回合的”上下文锚点”,比真正的用户输入还显眼。
四个现象在同一段对话里往往同时出现,彼此放大:早回答锚定错误 assumption,模型反复打补丁就变成 bloat,bloat 又把中间几轮真正的用户输入挤到 attention 分布的低谷。
几种补救方案的失败
RECAP(最后一轮汇总所有 shard):有改善但远不及 FULL,前几轮的错误 attempt 还在 context 里干扰。
SNOWBALL(每轮重发所有历史 shard):改善 15-20%,相对实用,代价是 context 越来越长。
降温度:T=0 下 sharded unreliability 仍有 30%。早期生成的微小随机分歧会级联放大,第一轮选不同的 clarification 措辞,整条对话路径就分叉了。
Prompt hint(提醒模型对话会是多轮 underspecified 的):+1%,可以忽略。
这几个失败的尝试比成功的修复更有信息量。Multi-turn 不可靠不是表层 prompt 工程能解决的,要么改训练,要么改 inference 协议。
几点引申
第一个错位是 benchmark 与真实使用脱节。我们用 90 分的模型做生产,90 分是 lab 条件下测出来的;同样的任务在真实 underspecified 多轮场景里可能只剩 50-60。这部分差距既不会出现在 leaderboard 上,也不容易归因,出错时用户大概率怪自己 prompt 没写好。
第二个错位是 agent 框架与 LLM 本体的责任划分。RECAP 和 SNOWBALL 实质上就是给 LLM 外挂记忆,让模型每轮都假装是 single-turn。Agent 框架如此流行,部分原因正是底层 LLM 多轮能力不行,应用层不得不补偿。但论文表明,agent 式拼接补偿不能完全拉回 FULL 水准,这是训练目标里的根本缺失。
第三个错位是 reasoning model 的承诺。o3 和 R1 加了大量 test-time compute,单轮领先,但 multi-turn unreliability 一样高。Reasoning 主要发生在已知充分信息之后,对”如何处理信息逐步揭露”这个 meta 层面没什么帮助。
实用层面,论文给用户的建议反而是最朴素的两条:如果当前对话感觉不对劲,重开一个新对话,把所有要求一次性写清楚;或者让 LLM 帮你把已有对话整合成一个完整 instruction,再用这个 instruction 重开。
这两条建议本身就说明了问题:本该模型做的事,目前还得用户自己来。
–文章来源《Finisky Garden》
Comments NOTHING