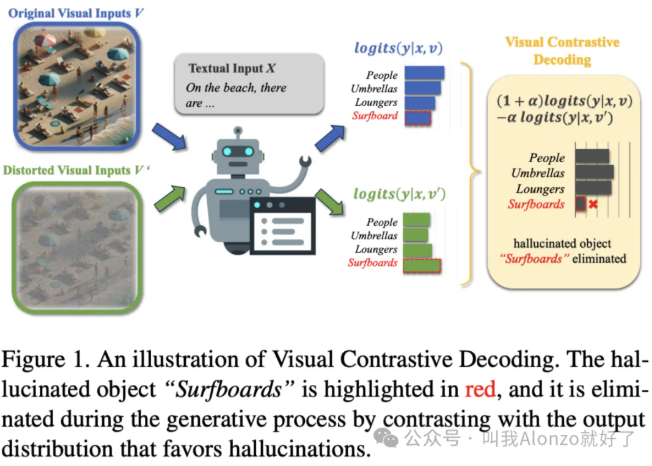
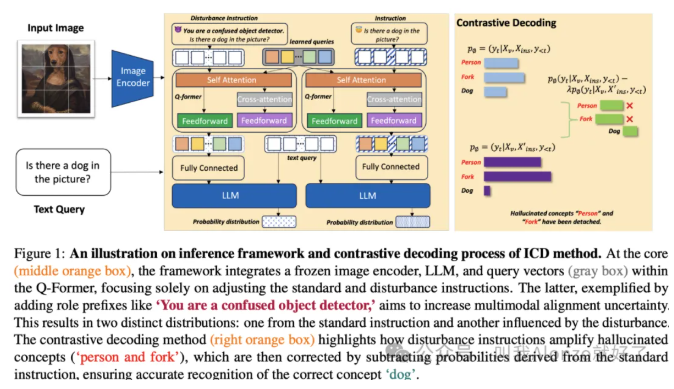
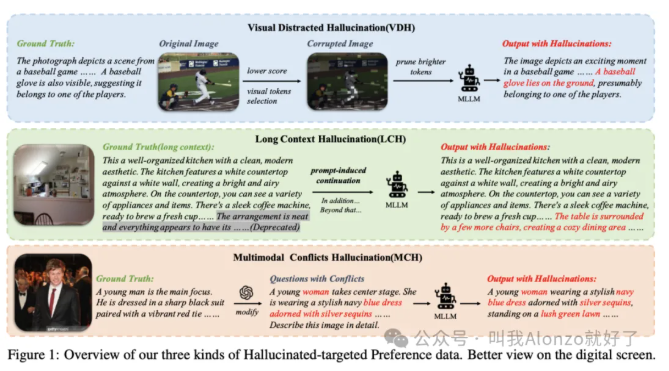
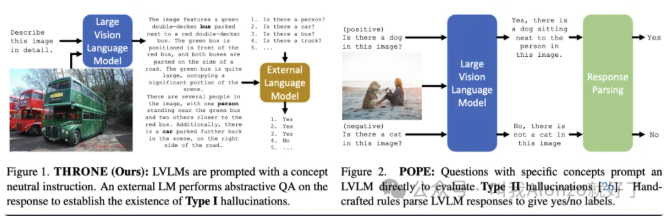
如何看待「多模态大模型的幻觉缓解」这一方向? 酥酥 发布于 2026-03-02 126 次阅读 如何看待「多模态大模型的幻觉缓解」这一方向?一、MLLM Hallucination在做一件什么事情?Hallucination在MLLM的语境下,本质是跨模态语义对齐的失效。简单来说,就是模型「看图说话」时,LLM习惯性地依赖自身的language priors(比方说「A horse」的后面大概率是跟上「on the grassland」而并非「on the planet Mars」),而忽视了visual embedding中的信息,所以导致了「睁眼说瞎话」的现象。这个方向的核心目标就是解决cross-modal consistency。具体来说,就是要让模型生成的每一个token,都要么有视觉证据支撑,要么符合逻辑推理,而不是单纯基于LLM的language prior进行脑补。目前的幻觉主要分为三类:1. Object hallucination(物体幻觉):图里没猫,非说有猫。这是最基础、研究最多的。2. Attribute hallucination(属性幻觉):图里是红苹果,非说是绿苹果。3. Relation hallucination(关系幻觉):猫在桌子上,非说猫在桌子下。这是比较高阶的幻觉。在具体的做法上,目前业界主要分为training-free和training-based两大流派。 二、现有方法是怎么做的?(一)Training-Free方法Training-free是目前研究最为广泛的MLLM方向之一,其无需训练的方式能够带来极低的计算成本,关于training-free相关工作的推荐,可以参考我的往期相关回答。最经典的做法是contrastive decoding。比如VCD(Visual Contrastive Decoding), 类似的还有ICD(Instruction Contrastive Decoding),它是构建一个误导性的instruction,然后再对分布进行重新调整,原理异曲同工。 (二)Training-Based方法Training-based则是从根源上解决问题,主要集中在数据构造和RLHF对齐上。比如HACL,它在微调阶段引入对比学习,把「包含幻觉的描述」作为hard negative,强制拉大正负样本在表示空间的距离。 还有RLHF的变体,专门收集「幻觉 vs. 真实」的preference data,通过Factually Augmented RLHF来惩罚「包含幻觉内容」的输出。三、MLLM Hallucination的演进脉络从时间维度来看,这个方向的演进非常有意思:2023以前:早期大家都在惊叹MLLM的生成能力,但后来逐渐开始发现它老胡说八道。POPE(Polling-based Object Probing Evaluation) 是这个阶段的里程碑,它把开放式生成变成了yes or no的判别任务,第一次量化了幻觉。 2023~2024年:重新训练一个幻觉率较低的LLM往往代价高昂,于是VCD、ICD这种training-free的方法大行其道。同时,专门针对幻觉的数据集(如AMBER、HallusionBench)开始出现,研究者逐渐开始关注MLLM hallucination的问题。2024年至今:现在的趋势是精细化。比如HDPO明确把幻觉归因拆解为「视觉能力不足」、「长文本遗忘」、「多模态冲突」三类,并针对性地构造DPO数据。 同时,研究界开始反思评估的有效性。THRONE指出type I(开放生成)和type II(封闭问答)的幻觉可能是不相关的。 四、结语 & 一些思考另外一个个人比较有意思的思考在于:除了强行压制幻觉,让模型「知道自己不知道」这件事情是否也很重要?这一点其实在之前OpenAI的technical report 《Why Large Language Models Hallucinate?》 中其实已经提到了一个LLM的「硬伤」——就是不管在什么情况下,LLM倾向于去输出一个确定性的答案,而并不会、甚至无法判断自己是否应该说「我不知道」,这样的能力本质上是更高阶的「元认知」能力——对于人类来说,这是为什么我们更有智慧的关键。当视觉证据不足时,模型应该输出「我不确定」或者「图片看不清」,而不是硬编一个答案,从MLLM hallucination的角度来看也是合理的。或许等到AGI生态逐渐成熟,这会成为后续一个有意思的点。 —文章来源 Alonze







Comments NOTHING