




论文标题:Exploring Diffusion Transformer Designs via Grafting
论文地址:https://arxiv.org/pdf/2506.05340
创新点
将预训练好的扩散Transformer(DiT)模型作为“脚手架”,通过编辑其计算图来低成本地探索和实例化新的架构设计,而无需从头开始进行昂贵的预训练。
成功地将标准的多头自注意力(MHA)和MLP替换为多种高效替代方案,包括MHA替代品,门控卷积(Hyena-X/Y)、局部注意力(滑动窗口)、线性注意力(Mamba-2)。MLP替代品,不同扩展率的MLP、卷积变体(Hyena-X)。
方法
本文提出了一种名为“嫁接”(grafting)的架构编辑方法,通过两阶段流程在预训练的扩散变换器(DiT)上实现新架构设计:首先利用激活蒸馏将原始算子的功能通过回归目标迁移到新算子,完成初始化;随后通过轻量级微调,在有限数据下缓解多算子替换带来的误差累积,从而在不从头训练的情况下,以不到2%的预训练计算成本,系统性地替换MHA和MLP为门控卷积、局部注意力、线性注意力等高效替代方案,构建出保持高质量生成效果且显著降低计算开销的混合架构,并进一步将连续变换器块并行化,把模型深度减半同时维持优越性能,为扩散模型架构研究提供了一种低资源、高效率的新范式。
嫁接框架总览——预训练扩散变换器的高效架构编辑方法与验证

本图以“架构编辑”视角系统呈现嫁接(grafting)范式:先以(a)之柱状对比揭示“从零训练”所需算力与“嫁接”所需算力数量级差异,奠定方法效率优势;继而在(b)以两阶段流程图阐释核心机制——阶段一通过激活蒸馏将预训练DiT之MHA/MLP输出作为回归目标,使新算子(如Hyena、SWA、Mamba-2等)在参数层面复现原算子功能,阶段二以少量数据端到端微调,抑制多算子替换所致误差传播,实现“即插即用”式算子替换;随之在(c)展示ImageNet 256×256类条件生成结果,验证50%交错替换下杂交架构FID仅较基线(2.27)上浮至2.38–2.64,视觉保真度无损;进而于(d)将实验尺度外推至2048×2048文本到图像任务,以PixArt-Σ为宿主,表明嫁接后模型在16k token长序列、多模态条件下仍获1.43×推理加速且GenEval下降不足2%,彰显跨任务泛化性;最后在(e)以“深度→宽度”重结构案例总结,通过将每相邻两层变换器块并行化,把28层压缩为14层,FID达2.77,优于同深度从零训练模型,证明嫁接不仅可替换算子,亦可重塑计算图拓扑。全图由方法动机、技术路线、质量验证、场景扩展至结构重设计,层层递进,完整刻画了“基于预训练模型的小算力架构编辑”这一新研究范式之可行性与潜力。
DiT-XL/2自注意力局部性度量及局部算子替换可行性分析
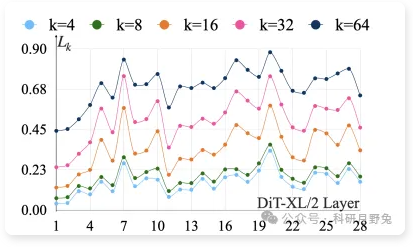
本图通过对DiT-XL/2全部28层自注意力矩阵的band-k局部性量化,揭示多数头仅聚焦邻近token:当k=32时,逾半数层之Lk>0.5,表明可安全以局部算子(滑动窗口、短卷积等)替代全局softmax注意力而不致长程依赖断裂;横轴层索引与纵轴Lk曲线共同呈现出“浅层偏全局、深层愈局部”的分布规律,为后续嫁接策略中“层选”与“替换比例”提供了可解释的理论依据。
面向MHA替换的线性复杂度门控卷积算子Hyena-X与Hyena-Y结构示意
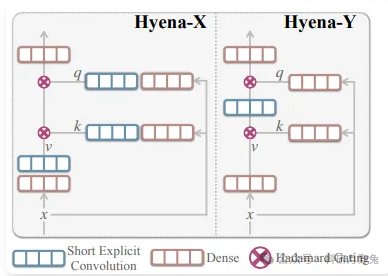
本图以结构化框图方式给出本文新提出的Hyena-X与Hyena-Y两种门控卷积算子的内部计算流:二者均保留“先投影-后局部门控-再融合输出”的通用骨架,通过取消或缩短隐式长卷积、仅保留少量显式短卷积核(K=4)实现线性复杂度,从而在序列维度上替代二次型MHA;同时以Hadamard乘积形式的门控机制保持跨通道交互能力,确保在嫁接替换后仍能复现原自注意力的局部依赖建模功能。
实验
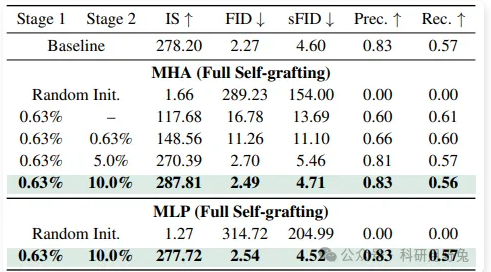
本表以“全层自我嫁接”这一纯控制变量实验,系统检验了 grafting 流程在「仅重初始化参数、不改变算子种类」的极限条件下,对 DiT-XL/2 生成质量的恢复能力,并量化阶段二(轻量化微调)所需数据规模的敏感曲线。实验设计将 28 个 MHA 与 28 个 MLP 全部替换为「同构但随机初始化」的对应算子,固定阶段一的激活蒸馏样本量为 8 k(约 0.63 % ImageNet-1K),仅改变阶段二的微调数据占比(0 %、0.63 %、5 %、10 %),从而剥离「架构变化」与「数据规模」两个因子。 结果呈现清晰的指数型收敛:当不提供任何微调数据时,模型立即崩溃,MHA 与 MLP 的 FID 分别高达 289.23 与 314.72,IS 接近 1,Precision/Recall 近于 0;一旦投入 0.63 % 数据,MHA 分支 FID 骤降至 11.26,显示阶段一蒸馏虽能大致对齐特征分布,但误差的逐层累积仍需端到端修正;继续将数据量提升到 5 %,FID 已逼近 2.70,与基线差距缩小至 0.43;当数据量达到 10 %(128 k 样本,约 24 h 8×H100 训练),MHA 与 MLP 的 FID 分别为 2.49 与 2.54,与原始 DiT-XL/2 的 2.27 仅差 0.22–0.27,IS、Precision、Recall 亦几乎重合,证实 grafting 框架本身即可在「无架构改动」情况下完成质量复原。
–文章来源《科研月野兔》
Comments NOTHING