在 In-Context RL 的研究热潮中,往往存在一种惯性思维,认为只要把 Transformer 做大,把上下文窗口拉长,模型就能像 AD (Algorithm Distillation) 或 DPT (Decision-Pretrained Transformer) 那样“顿悟”出最优策略。
然而实验结果表明,现有的 In-Context RL 方法存在显著局限。它们本质上更接近于条件行为克隆。
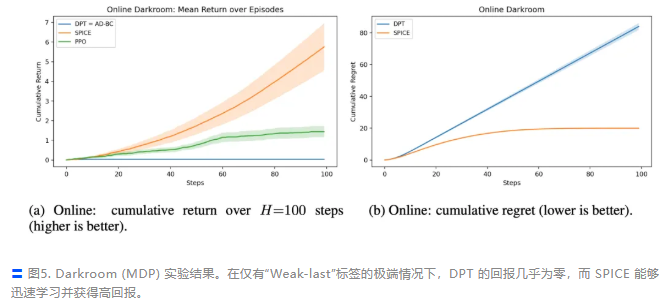
如果你喂给模型的是专家数据,它能模仿得很好。但如果上下文里充斥着次优甚至随机的轨迹(这在实际应用中才是常态),模型往往会拟合这些次优行为,从而继承了策略偏差,难以超越演示者的水平。
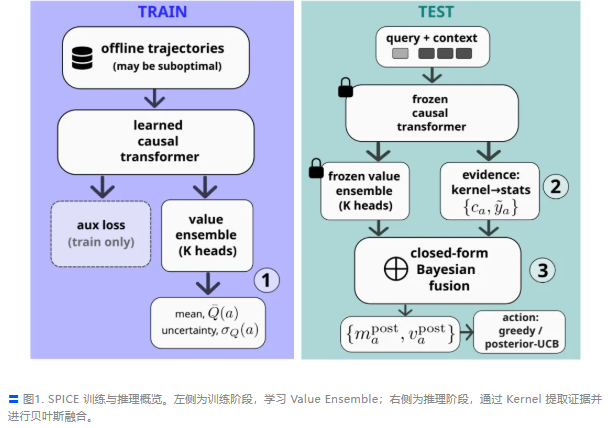
近日,由 Yoshua Bengio 领衔的 Mila 实验室团队发布了一项新工作 SPICE,这项工作并没有在模型参数量上死磕,而是将深度集成 (Deep Ensemble)、贝叶斯推断与 Transformer 进行了优雅的结合。
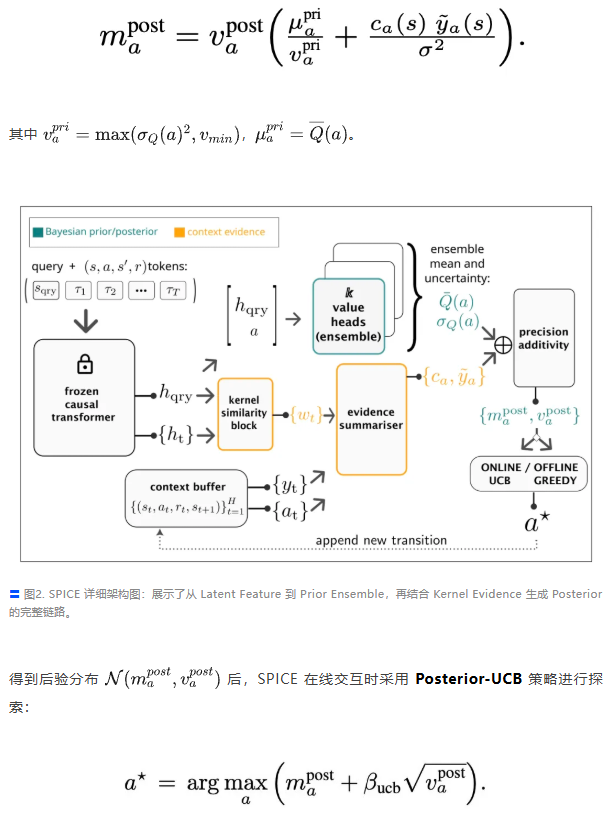
SPICE 的核心洞察在于,不要把预训练模型仅仅当作一个动作预测器,而应将其视为一个提供“价值先验”的工具。
在测试时(Test-time),通过显式的贝叶斯公式将这个先验与上下文证据融合,利用 UCB(置信上界)算法进行决策。
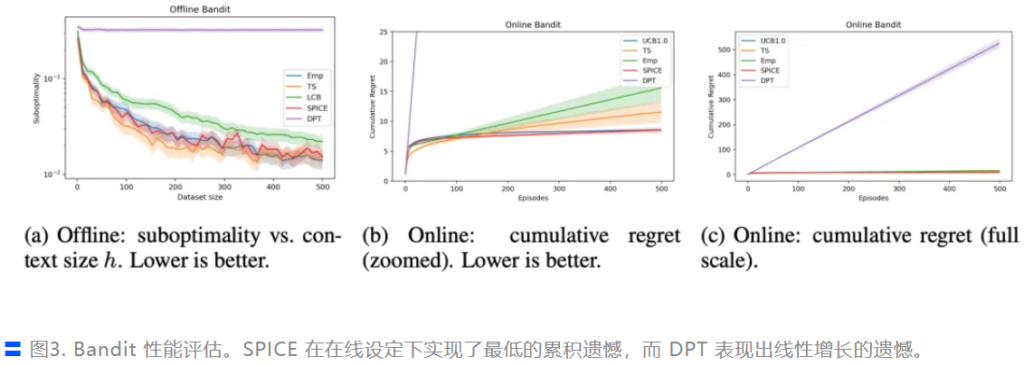
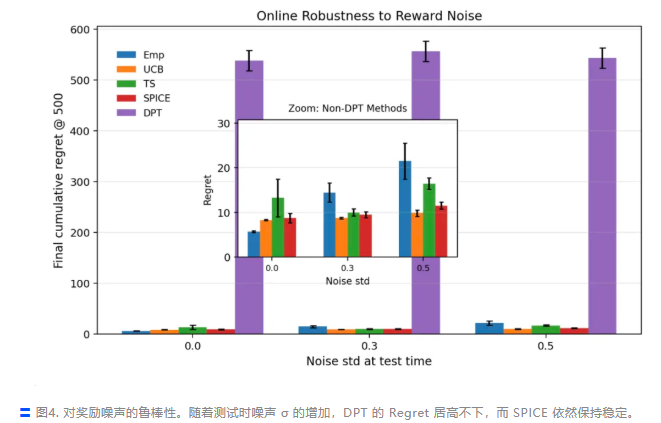
即便是在预训练数据质量极差的情况下,SPICE 依然在理论上被证明具有对数级遗憾界 (Logarithmic Regret),并在实验中展现出显著优于 DPT 等基线模型的性能。












Comments NOTHING