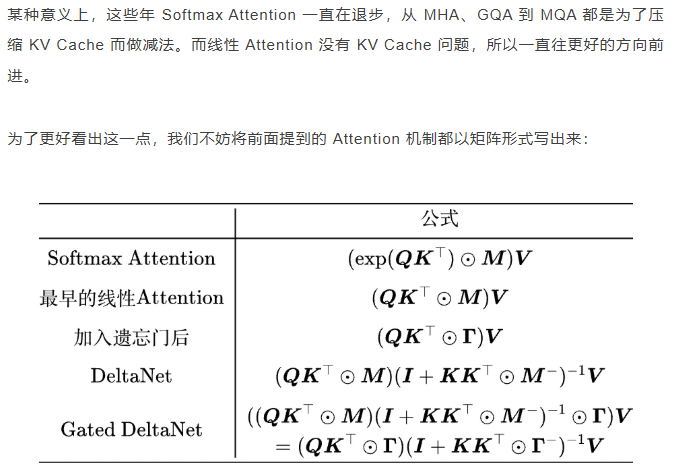
线性注意力简史:从模仿、创新到反哺 酥酥 发布于 2025-09-19 181 次阅读 在中文圈,笔者应该算是比较早关注线性 Attention 的了,在 2020 年写首篇相关文章线性Attention的探索:Attention必须有个Softmax吗?时,大家主要讨论的还是 BERT 相关的 Softmax Attention。事后来看,在 BERT 时代考虑线性 Attention 并不是太明智,因为当时训练长度比较短,且模型主要还是 Encoder,用线性 Attention 来做基本没有优势。对此,笔者也曾撰文线性Transformer应该不是你要等的那个模型表达这一观点。直到 ChatGPT 的出世,倒逼大家都去做 Decoder-only 的生成式模型,这跟线性 Attention 的 RNN 形式高度契合。同时,追求更长的训练长度也使得 Softmax Attention 的二次复杂度瓶颈愈发明显。在这样的新背景下,线性 Attention 越来越体现出竞争力,甚至出现了“反哺”Softmax Attention 的迹象。 原则上, Q,K的 d 与 V,O 的 d 可以不一致,比如 GAU 和 MLA 便是如此,但将它们简化成同一个并不改变问题本质。 标准的 Softmax Attention,通常是指 Attention is All You Need 所提的 Attention 机制: 注意这里出现了“线性 RNN”,它是更广义的概念,线性 Attention 属于线性 RNN 的一种,线性 RNN 也单独发展过一段时间,比如之前介绍过的 LRU、SSM 等,但最近比较有竞争力的线性架构都具有线性 Attention 的形式。早年的线性 Attention 还有一些非常明显的模仿 Softmax Attention 的特点,比如会给式(6)加入分母来归一化,而为了归一化,那么KQ就必须非负,于是又给QK加上了非负的激活函数,以 Performer、RFA [2] 为代表的一系列工作,更是以近似exp(KQ)为出发点来构建模型。 然而,后来的研究如《The Devil in Linear Transformer》[3] 发现,在序列长度维度归一化并不能完全避免数值不稳定性,倒不如直接事后归一化,如: 注意,衰减因子在 RetNet 前也有,不过它们多以线性RNN的形式出现,如上一节提到的LRU、SSM 等,RetNet 应该是首次将它跟线性 Attention 结合起来。加入衰减因子后,模型会倾向于遗忘掉更为久远的历史信息,从而至少保证最近 token 的分辨率,说白了就是跟语言模型特性相符的“就近原则(Recency Bias)”的体现,从而往往能工作得更好。 此外,一个值得关注的细节是 RetNet 还给Q,K加上了 RoPE,这相当于将衰减因子推广到复数γe^{iθ},从 LRU 的角度看则是考虑了复数的特征值。 尽管给 RNN 加位置编码的操作看上去似乎有点违和,但有些实验比如最近的 TransXSSM [6] 表明,给线性 Attention 加 RoPE 也有一定的正面作用。当然,这可能取决于具体的模型变体和实验设置。 其中,并行化的“通解”是转化为 Prefix Sum [10] 问题然后 Associative Scan,大体思路我们在Google新作试图“复活”RNN:RNN能否再次辉煌?的“并行化”一节也简单介绍过。然而,“通解”并不是 GPU 高效的,GPU 最高效的是矩阵乘法,所以找到大量使用矩阵乘法的并行算法是最理想的,甚至都不用并行,只要找到充分使用矩阵乘法的 Chunk by Chunk 递归格式,都能明显提高训练效率。这反过来对模型提出了要求,如只有外积形式的遗忘门才能实现这个目的,典型反例就是 Mamba,它是非外积的遗忘门,无法充分发挥 GPU 的性能,所以才有了后续 Mamba2 和 GLA [11] 等变化。 这跟 RNN 有什么关系呢?很简单,优化器如 SGD、Adam 等,它们本质上就是一个关于模型参数的 RNN!其实这个观点并不新鲜,早在 2017 年 Meta Learning 盛行那会就已经有研究人员提出并利用了这点,只不过当时的想法是尝试用 RNN(LSTM)去模拟一个更好的优化器,详情可以参考《Optimization as a Model for Few-Shot Learning》[13]。 TTT 原文则致力于探索 mini-batch 下的非线性 RNN,后来的 Titans [14] 则给 TTT 的 SGD 加上了动量,再后面《Test-Time Training Done Right》[15] 则探索了 large-batch 的 TTT 用法,还探索了“TTT + Muon”的组合。 其中: 我们在Transformer升级之路:旋转位置编码的完备性分析指出,对于任何正交矩阵Ω, — 站长评论:我看到现在写得最好的线性Attention的工作,故引用至此,来自PaperWeekly。
































Comments NOTHING