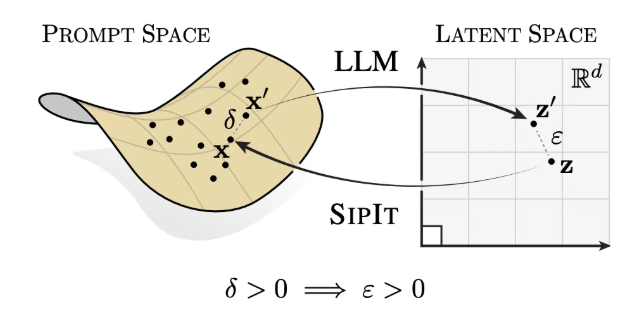
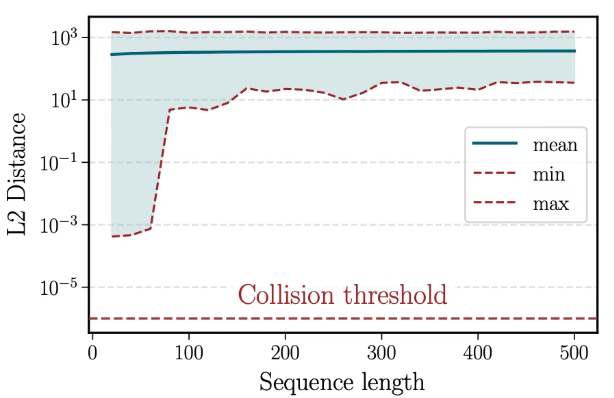
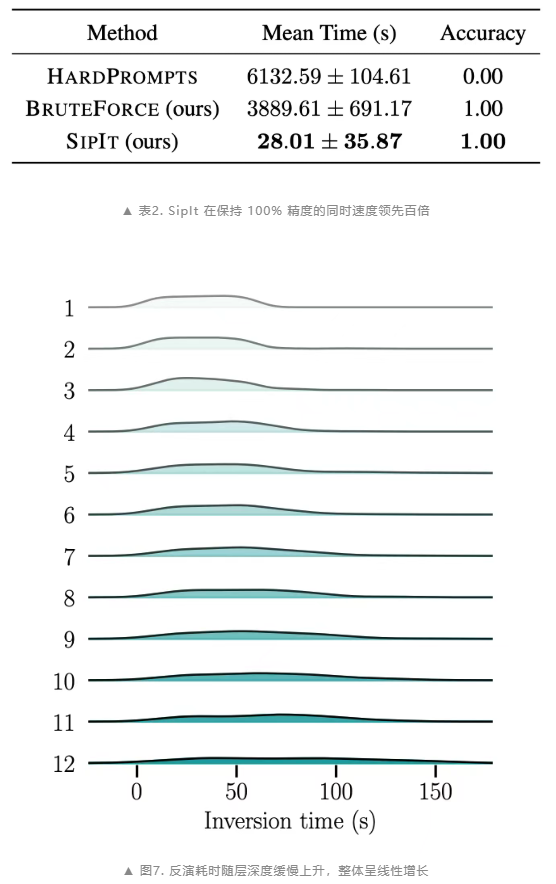
你的输入,LLM一字未忘:Transformer被证明“几乎处处可逆” 酥酥 发布于 2025-10-30 83 次阅读 人们一直以为,大模型的隐藏状态是抽象的“语义压缩”。但这篇论文发现,Transformer 并没有丢掉任何输入信息——它能凭隐藏状态精确反演出你说的每一个字。 我们一直以为,语言模型的隐藏状态是对输入的一种“压缩”或“抽象”。在这层抽象里,模型似乎丢掉了表面信息,只保留“语义精华”——这就是我们所说的“理解”。但这篇论文颠覆了这个想法。作者发现,在标准的 Transformer 结构下,模型的最后一 token 隐状态几乎必然能唯一确定输入序列。换句话说,只要你知道这个隐藏状态,就能反推出原文。而且,这个性质不仅在随机初始化时成立,在整个训练过程中也不会被破坏。更令人震撼的是,他们没有停留在数学证明,而是进一步提出了一个实际算法——SipIt(Sequential Inverse Prompt via Iterative Updates)。它不需要任何外部模型训练,仅凭 Transformer 的隐藏状态,就能把输入一个 token 一个 token 地完整还原。 论文标题:Language Models are Injective and Hence Invertible论文链接:https://www.arxiv.org/pdf/2510.15511 01 研究背景:为什么单射性如此重要?在 Transformer 的每一层里,我们都能看到“似乎会丢信息”的环节:LayerNorm 会重标尺度,残差连接可能抵消特征,注意力层还会把多个 token 混合成一个上下文表示。这些操作看起来都不利于可逆性。然而作者从另一个角度切入——解析性(real-analyticity)。他们将 Transformer 视为从离散序列到连续表示的解析映射: 02 方法:SipIt如何“倒放”Transformer?有了理论基础,作者提出了一个问题:如果隐藏状态真的能唯一对应输入,我们能否直接把原文还原回来?他们的答案是——可以。核心思路 03 极限穷举测试:仍未出现碰撞为避免采样偏差,作者挑出最相似的 10 对前缀,并穷举词表的所有接续组合——相当于检索上千亿条输入。即便在这个极端测试下,隐藏状态的最小距离依然大于 0。 他们还观察了距离随序列长度变化的趋势:短句在前几层迅速拉开间距,长句则趋于稳定。 反演实验:SipIt 的可行性验证在 GPT-2 Small 上,作者选取 100 条提示序列,仅使用隐藏状态进行反演。SipIt 实现了 100 % token-level 精确恢复,反演耗时与序列长度线性增长。 04 总结这项研究并未改动模型结构,却动摇了我们对“隐藏表示”的长期假设。Transformer 的最后一 token 隐藏状态在解析意义上几乎处处可逆:不同输入有不同表示,训练过程不会破坏这种区分性。SipIt 把理论转化为工具——在不训练任何外部网络的前提下,仅凭隐藏状态就能线性时间重建原文。从科研角度,这为解释 LLM 内部表征提供了坚实起点;从工程角度,这提醒我们:缓存隐藏状态等价于缓存用户输入,隐私治理必须覆盖这一层;从方法论角度,它展示了一种范式——先证明结构,再把结构做成算法。也许我们需要重新定义“理解”与“记忆”的界限。 至少从这篇论文的结果看——LLM 没有忘记你说过的每一个字。 —文章来源<paperweekly>









Comments NOTHING