



创新点
提出了 极性感知线性注意力 (Polarity-aware Linear Attention),显式建模 query-key 的正负交互,解决了传统线性注意力丢失负值信息的问题
引入 可学习的极性混合系数矩阵 (Gs, Go),替代简单的减法操作,稳定地结合同号与异号交互
理论上证明了通过 正的一阶与二阶导数的函数 可以降低注意力分布的熵,从而恢复 softmax 的“尖锐性”
实现了一个 逐通道可学习幂函数 rescaling,既保证了非负性,又恢复了 softmax 类似的稀疏性
在 ImageNet、COCO、ADE20K、LRA 等多任务上验证了性能与效率的兼顾,提升最高达 +4.6%
方法
整体结构
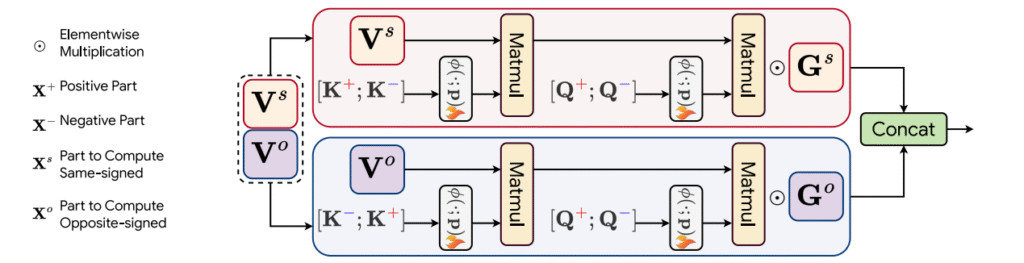
Query-Key 分解:将 Q、K 拆分为正/负部分,得到四类交互(同号:正-正、负-负;异号:正-负、负-正)
双流处理:Value 向量在通道维度一分为二,分别对应同号交互流与异号交互流
极性系数矩阵 Gs/Go:对两个流的输出加权融合,学习两类交互的互补性
幂函数缩放:对 Q/K 映射引入逐通道可学习幂次 rescaling,降低熵,使注意力分布更尖锐
卷积增强:可选引入 DWC/DCN 升秩,避免低秩退化
即插即用模块作用
PolaLinearAtt 适合在高效 Transformer 中即插即用,尤其在高分辨率视觉与长序列任务中,能以线性复杂度恢复更接近 softmax 的判别力与稀疏性
适用场景:高分辨率视觉任务:如目标检测、语义分割、实例分割,需要在大图像上高效建模全局依赖
长序列任务:如长视频建模、长文本处理(LRA 等),线性复杂度能有效降低显存和计算压力
资源受限环境:移动端或边缘设备部署,既要节省算力又要保持较好性能
对细粒度关系敏感的任务:需要区分强/弱相关性或正/负相关性的场景(如小目标检测、细粒度分类)
模块作用:补全负值交互:传统线性注意力丢失负值信息,PolaLinearAtt 显式建模正负交互,使注意力更接近原始 softmax
增强注意力稀疏性:通过幂函数缩放降低熵,恢复“尖锐”的注意力分布,提升模型判别力
效率与性能兼顾:保持线性复杂度,显著提升分类、检测、分割任务的精度
即插即用:可直接替换 Transformer 的自注意力模块,不改变整体结构
即插即用模块
import torch
import torch.nnasnn
class PolaLinearAttention(nn.Module):
def __init__(self, dim, num_patches, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1,
kernel_size=5, alpha=4):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.head_dim = head_dim
self.qg = nn.Linear(dim, 2 * dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
self.dwc = nn.Conv2d(in_channels=head_dim, out_channels=head_dim, kernel_size=kernel_size,
groups=head_dim, padding=kernel_size // 2)
self.power = nn.Parameter(torch.zeros(size=(1, self.num_heads, 1, self.head_dim)))
self.alpha = alpha
self.scale = nn.Parameter(torch.zeros(size=(1, 1, dim)))
self.positional_encoding = nn.Parameter(torch.zeros(size=(1, num_patches // (sr_ratio * sr_ratio), dim)))
print('Linear Attention sr_ratio{} f{} kernel{}'.
format(sr_ratio, alpha, kernel_size))
def forward(self, x, H, W):
B, N, C = x.shape
q, g = self.qg(x).reshape(B, N, 2, C).unbind(2)
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
x_ = self.norm(x_)
kv = self.kv(x_).reshape(B, -1, 2, C).permute(2, 0, 1, 3)
else:
kv = self.kv(x).reshape(B, -1, 2, C).permute(2, 0, 1, 3)
k, v = kv[0], kv[1]
n = k.shape[1]
k = k + self.positional_encoding
kernel_function = nn.ReLU()
scale = nn.Softplus()(self.scale)
power = 1 + self.alpha * torch.sigmoid(self.power)
q = q / scale
k = k / scale
q = q.reshape(B, N, self.num_heads, -1).permute(0, 2, 1, 3).contiguous()
k = k.reshape(B, n, self.num_heads, -1).permute(0, 2, 1, 3).contiguous()
v = v.reshape(B, n, self.num_heads, -1).permute(0, 2, 1, 3).contiguous()
q_pos = kernel_function(q) ** power
q_neg = kernel_function(-q) ** power
k_pos = kernel_function(k) ** power
k_neg = kernel_function(-k) ** power
q_sim = torch.cat([q_pos, q_neg],dim=-1)
q_opp = torch.cat([q_neg, q_pos],dim=-1)
k = torch.cat([k_pos, k_neg],dim=-1)
v1,v2 = torch.chunk(v,2,dim=-1)
z = 1 / (q_sim @ k.mean(dim=-2, keepdim=True).transpose(-2, -1) + 1e-6)
kv = (k.transpose(-2, -1) * (n ** -0.5)) @ (v1 * (n ** -0.5))
x_sim = q_sim @ kv * z
z = 1 / (q_opp @ k.mean(dim=-2, keepdim=True).transpose(-2, -1) + 1e-6)
kv = (k.transpose(-2, -1) * (n ** -0.5)) @ (v2 * (n ** -0.5))
x_opp = q_opp @ kv * z
x = torch.cat([x_sim, x_opp],dim=-1)
x = x.transpose(1, 2).reshape(B, N, C)
if self.sr_ratio > 1:
v = nn.functional.interpolate(v.transpose(-2, -1).reshape(B * self.num_heads, -1, n), size=N, mode='linear').reshape(B, self.num_heads, -1, N).transpose(-2, -1)
v = v.reshape(B * self.num_heads, H, W, -1).permute(0, 3, 1, 2)
v = self.dwc(v).reshape(B, C, N).permute(0, 2, 1)
x = x + v
x = x * g
x = self.proj(x)
x = self.proj_drop(x)
returnx
if __name__ == "__main__":
# 将模块移动到 GPU(如果可用)
device = torch.device("cuda"if torch.cuda.is_available() else"cpu")
# 创建测试输入张量 (batch_size, H * W, channels) / B N C
x = torch.randn(1, 64, 128).to(device)
# 初始化 pla 模块
pla = PolaLinearAttention(dim=128, num_patches=64, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1,
kernel_size=5, alpha=4)
print(pla)
pla = pla.to(device)
# 前向传播
output = pla(x, H=8, W=8)
# 打印输入和输出张量的形状
print("输入张量形状:", x.shape)
print("输出张量形状:", output.shape)
Comments NOTHING