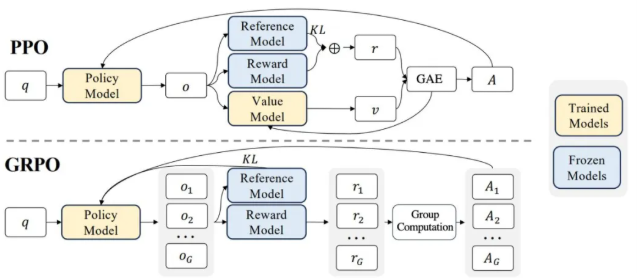
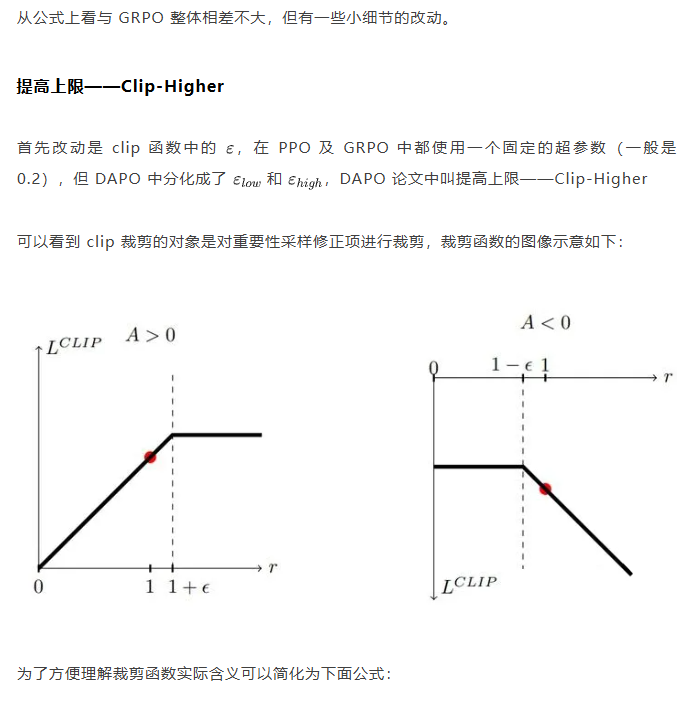
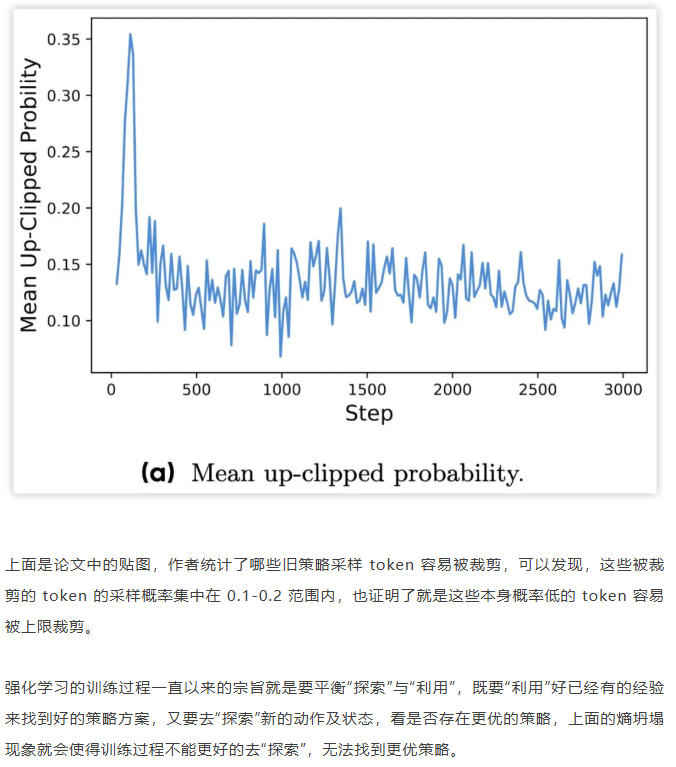
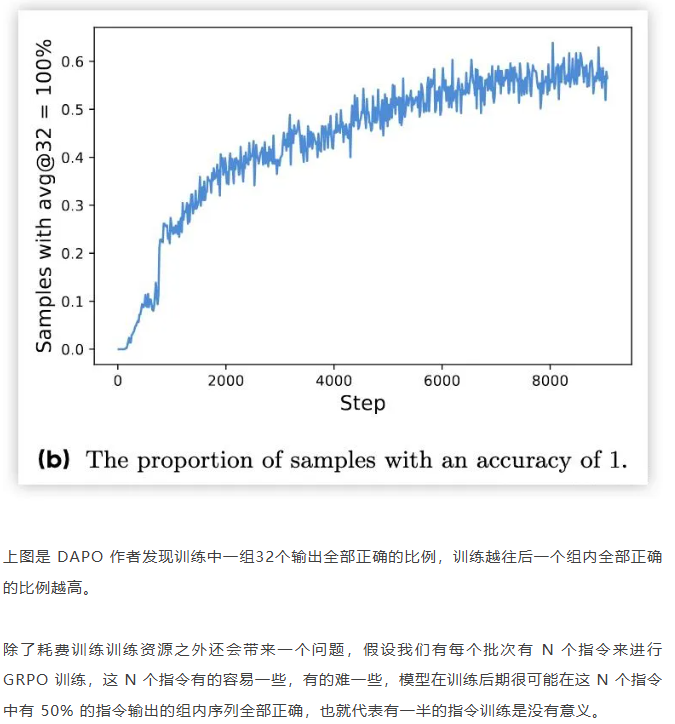
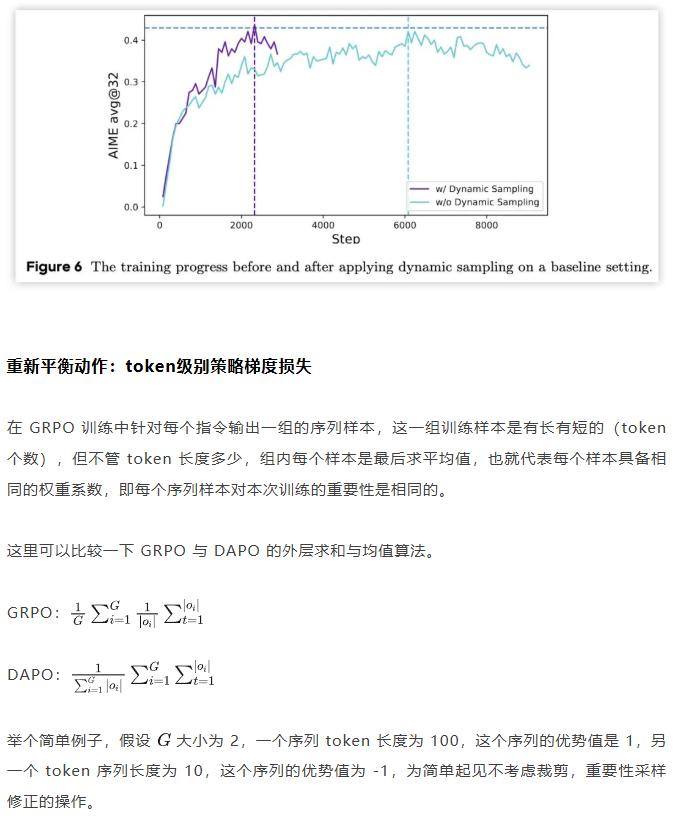
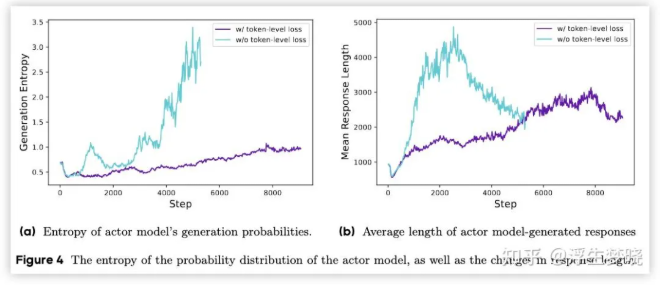
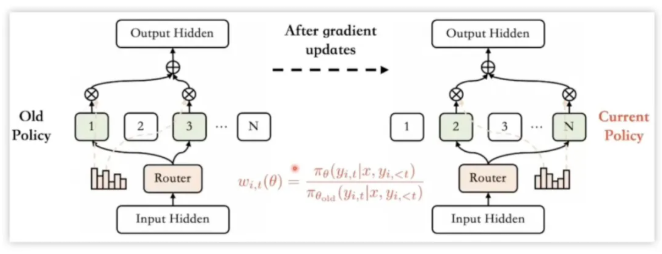
类PPO强化学习三部曲:GRPO简化→DAPO修正→GSPO全面进化 酥酥 发布于 2025-10-20 75 次阅读 本文虽然标题中提到“类 PPO 算法”,但更准确地说,DAPO 和 GSPO 都可以视作在 GRPO 框架下,针对不同任务场景的一系列演进方案。它们并非简单的替代,而是通过改进策略更新与约束机制,逐步修正了 GRPO 在实践中暴露出的若干缺陷。这一脉络不仅揭示了算法间的继承关系,也能帮助我们更清晰地理解 PPO 系列方法在强化学习中的演化逻辑。 那么,GRPO 究竟存在哪些问题?DAPO 与 GSPO 又分别从哪些角度切入,提出了怎样的改进?接下来,我们就沿着这一条演进主线,逐步拆解背后的动机与机制。 01 PPO简单说明 为了后文内容连贯性,这里再简单介绍一下 PPO 算法,PPO 算法在 LLM 上的初始应用是作为模型输出内容的一种偏好调节,旨在使得模型输出更贴合人类偏好的回答内容。在这个过程中需要让人类去针对问题进行排序标注,使用排序标注好的模型来训练奖励(RM)模型以及价值(Value)模型,一般初始的奖励模型和价值模型是同一个模型(也有使用不同模型的情况),区别在于 RLHF(人类偏好强化训练)过程中价值模型会进行参数更新,而奖励模型则仅进行推理输出奖励值。下面是 PPO 中 Actor 模型,也就是我们目标主模型的强化学习训练目标函数: 优势函数其中优势函数计算方式有很多种,其公式为: 可以看到 PPO 算法涉及到了 4 个模型,更主要的是奖励模型需要提前进行训练,而价值模型也是一个 LLM,这就造成两个问题。首先奖励模型的训练工作很复杂,虽然 DPO 算法可以通过绕过奖励模型的方案来训练,但 DPO 需要构造负样本,负样本与正样本的质量会影响训练的结果。其次状态价值是由一个 LLM 给出的,这个值具备不确定性,也就是说价值模型提供的状态价值可能不准确,这样也就使得 PPO 训练过程变得极其脆弱。我们的目标是来最大化目标函数,价值模型预估偏差会使得 Actor 模型参数梯度往错误方向走一大步,很容易造成训练崩溃。另外还有一点考虑,我们之前是对 LLM 输出内容进行人类偏好的强化学习训练,人类偏好本身是没有固定规则的,因此才需要去训练奖励模型来进行 LLM 输出内容是否符合人类偏好的打分。但对于程序,数学等任务是具备规则特性的,对于一个程序任务或者数学任务,LLM 输出结果是可以使用规则来判断正确性的,这也是 GRPO 提出的一个前提。 02 GRPO GRPO 中一般存在两个模型,主模型 Actor 模型以及参考模型,这两个模型初始时是同一个模型,但训练过程中参考模型只作为 KL 散度约束项来防止主模型训练中权重偏离原始模型权重太多。PPO 中奖励模型更换成了特定的规则函数来进行奖励值打分,PPO 中的价值模型则直接取消,优势函数的计算更换成了 LLM 一组输出的奖励值标准化的形式。GRPO 目标函数: 03 DAPODAPO 引言部分就提到了其训练 GRPO 时出现了熵坍塌、训练不稳定、奖励噪声的问题,这也对应了上面我们分析的几个 GRPO 固有缺陷,这一点 DeepSeek 应该是有应对的 Trick,但论文中并没有提到。DAPO 是字节的工作,因此开源代码也就使用的 verl,其针对 GRPO 存在的问题提出来解耦裁剪和动态采样策略优化(Dynamic sAmpling Policy Optimization DAPO)。另外 DAPO 应对的场景是长 COT 场景, 也就是带思考模式的输出情况(上面也提到,当生成序列如果很长,重要性采样修正项会造成方差偏移的累积)。下面是 DAPO 针对 GRPO 做的修正工作:移除KL散度上面的 PPO 及 GRPO 目标函数中都存在 Actor 模型与参考模型的 KL 散度,KL 散度的意义也说过了,就是不想让训练的模型与最初始模型分布差距太大。但 DAPO 的训练方案应对场景是有长思维链输出(带思考过程)情况,长输出也就代表着对于输出 token 分布调整更大,那么训练后的模型就必然会与原始模型存在很大差异,因为目标就是让他们有差异,因此KL散度的约束反而不是必需的了,所以可以移除。DAPO公式及创新点 随着模型训练到后期,每个批次中全为 1 的指令占比会更高。这会使得强化学习训练方差变大,因为我们输入指令让模型产生组内输出的过程实际是生成旧策略模型输出分布的过程。只有指令足够多,旧策略模型输出的序列足够多才能更准确的表示旧策略的输出分布,当有效指令变少的时候,旧策略模型输出的分布也就存在一定的偏移,换句话说就是存在方差,也就是说 GRPO 越到训练后期训练的方差偏移越大。关于解决这个问题 DAPO 也是简单粗暴,对于批次内生成的组内序列全部正确或错误的指令直接剔除掉,使用新的输出组中不全是错误或正确的指令来补充上,直到补全这个批次。这个方法粗看会影响训练效率,因为你需要让每条指令去生成一个组,再去使用奖励函数判断才能知道输出的组中序列是否全部正确或错误,但是作者实验发现这种方法可以更快的让模型收敛,也就是说可以平衡掉 GRPO 耗费的资源,甚至更优。下图是对照实验,紫色是使用动态采样的方案,蓝色是不使用动态采样的方案,很明显紫色更快收敛。 如果使用 GRPO 计算,则最后的结果为 0(此时只代表目标函数值标量为 0,但反向传播是看的梯度,梯度一般不为 0),而如果使用 DAPO 计算则结果为 ,在计算过程中大家就能感受到如果使用 GRPO 的方法是没有考虑 token 粒度的。也就是说在同一个样本中每个 token 所占的权重系数随着 token 长度的增加而减小,这样的话模型输出序列的长度越长,每个 token 在训练中对应的概率调整的幅度就越小。如果还是不太懂的话可以从策略梯度定理的角度来看,我们分别对 GRPO 和 DAPO 的目标函数算梯度公式。GRPO 梯度公式: 从梯度函数中可以更明显的看到 GRPO 中样本级别与 DAPO 中 token 级别计算的区别,从梯度的角度可以更好理解 GRPO 长 token 序列对于每个 token 权重的稀疏化对于梯度计算的实际影响。与上面同样的理解,不再赘述。另外还有一点是可以从梯度公式上看出来:对于一个每个 token 的梯度贡献来说,由于每个 token 的优势都是相同的,那么主要贡献值其实就来自于这个 token 的重要性采样修正项。而且从梯度公式后面看到(大括号内)一旦该 token 的重要性采样修正项被 clip 裁剪,那么这个 token 实际上对于梯度更新是没有任何作用的,也就是说被裁剪的 token 实际上对于 GRPO 训练没有任何帮助,从这一点上来重新思考 DAPO 去提升 Clip 裁剪上限也是有意义的。GRPO 这个问题的影响是长 token 序列的训练中每个 token 的修正幅度慢,比如对于长思维链的输出,假如最终推导结果正确,无论思维的过程很优质还是思维过程很差,该组的训练都不会对中间过程的 token 有较大的修正,比如优质内容的 token 采样概率应该增大,很差的思维过程 token 采样概率应该减小。而 DAPO 的修正方案是对组内全部 token 赋予相同的权重系数,这样就可以从 token 粒度来进行梯度的更新,解决上述问题。 上图是对照实验,紫色是 DAPO 在 token 级别计算损失,蓝色是样本级别计算损失,可以明显看到紫色曲线无论生成分布的熵值还是输出内容长度都更平稳。长序列的奖惩这一部分并不是针对 GRPO 公式的修正,而是对于带思考过程的长序列训练的一个 trick,其背景在于一般情况下在进行训练时考虑到模型输出长度限制会对于很长的内容进行截断。对于被截断的内容直接粗暴的给一个惩罚分值(负分),但忽略了可能这个长序列推导过程是正确的只是有点啰嗦,这种直接给负分会使得模型误认为这个推理逻辑是错误的。因此 DAPO 做了个动态的长度奖惩机制,让模型训练有个缓存,可以意识到是长度带来的惩罚而不是逻辑内容错误带来的惩罚,具体动态惩罚函数: 这个函数没有什么可说的,简单明了。整个 DAPO 是对 GRPO 的修正,提出了 4 个创新点,附上伪代码,读起来一目了然: 04 GSPOGSPO 全称是 Group Sequence Policy Optimization,组序列策略优化。是qwen3 团队的工作,该工作也是对 GRPO 的改进,不同于 DAPO 是应对带思考的长文本场景,GSPO 应对的场景是 MOE 模型的训练(当然还有对 GRPO 算法的一般性改进,参考前文 GRPO 的思考)。优化背景GSPO 提到的一个 GRPO 关键性缺陷在于重要性采样修正项使用的粒度不对,GRPO 中是对序列中每个 token 进行的重要性采样,因为动作的粒度是 token,但是奖励却是对整个序列的奖励,这样会造成一种逻辑冲突的问题。其实这个问题其他论文中也讨论过(忘记哪篇论文了),我们训练优化的目标是 token 的采样概率,这一点使用 token 作为动作粒度可以理解。但 GRPO 却是对一个序列整体奖惩,优化单元与奖惩单元粒度上不一致时的模型训练就容易出现偏差。其实上面这个观点如果站在未简化的强化学习算法的角度上来讲(PPO 或者 A2C),优势应该是动作级别的,但是对于 LLM 的自回归输出场景来说动作级别的优势是不太容易计算的,上面介绍 RLHF 的时候也提到了,需要有奖励模型和价值模型。但 GRPO 的简化方案使得每个 token 共享该序列整体的优势值,那粒度上对不齐也是必然的。从理论上来说带来的结果就是无法从 token 粒度上更快速的让模型提升正确 token 的采样概率。就比如重要性采样思考中提到的如果使用 GRPO 进行 on policy 训练,当不可以重要性采样修正项时,从目标函数梯度上看 GRPO 的 on policy 训练就成了 SFT 训练,对每个 token 一视同仁。除了上面问题外还有一个很重要问题是关于重要性采样修正项本身的,在上文中详细介绍了重要性采样的概念,这个概念是围绕两个分布展开的,涉及到分布,在统计学上是使用大数定律来近似一个分布的。通俗点说就是需要随机采样非常多的样本才能用这些样本的概率分布来近似整体的分布,在传统强化学习中也有蒙特卡洛方法(可以理解成随机采样)来近似模型的策略分布。但 GRPO 中的重要性采样修正项是如何计算的呢?它是计算新旧两个模型在某个 token 位置输出一个特定 token 的概率,使用这 1 个特定 token 样本的概率来代替该 token 位置的整个动作空间分布的概率,这样就极容易造成方差偏移的问题(这是上面介绍重要性采样方差公式的具体场景)。这个实际 token 的概率很困难随机性原因偏高或偏低(也就是方差),随着输出序列的增长,这种方差是会累积的(因为自回归的特性,每个 token 的采样概率依赖之前 token),前面有 GRPO 目标函数的梯度公式,对组内每个样本 token 会累加求均值,方差累积后求均值是不会消失的。除了以上的内容,GSPO 算法的出发点其实源自于 MOE 模型与 Dense 模型的区别,在 Dense 模型上使用 GRPO 训练模型不会有很大训崩的概率,但 MOE 模型上训崩概率很大。从下图示意原因就很明显: 区别在于新旧两个模型在进行序列中每个 token 概率计算时会被专家路由器路由到不同的专家模块,这样的话会造成重要性采样修正项变得极其不稳定,很容易被裁剪,被裁剪就会使得这个 token 在训练中没有任何的梯度贡献。还有一点使用旧策略模型激活的专家获得的分布来训练当前策略激活的专家梯度,这样训练到最后会使得专家功能混乱,基于以上原因可以得出结论,在 MOE 模型上使用 token 作为优化的动作粒度是不合理的。GSPO算法上面的背景中问题的本质就是奖励粒度与优化的动作粒度不一致问题,很自然的想法就是既然无法将奖励粒度细化到 token 的动作粒度,那能不能将动作粒度上升到奖励的序列粒度?也就是重要性采样修正不再对应 token 级别,而是对应序列级别,这也是 GSPO 做的工作。GSPO 目标函数公式: 至于 GSPO 后面提到的 GSPO-token,个人感觉没有太大分析的必要,只是又从 token 角度上推导了一下公式,理解上没有什么区别。

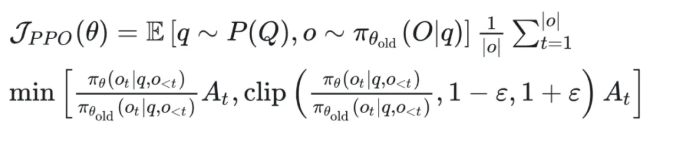
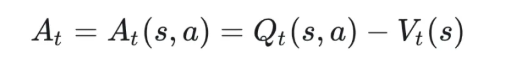


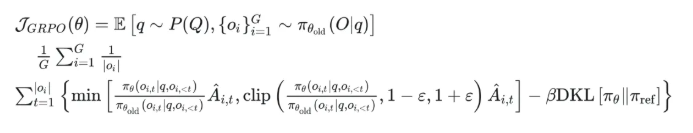






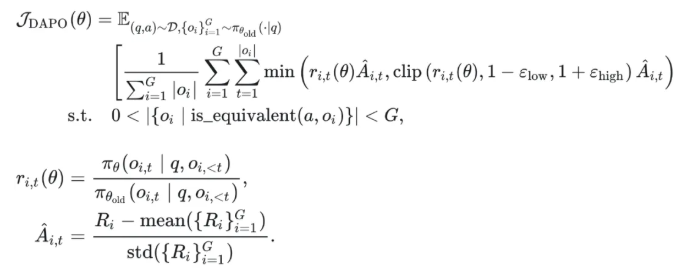



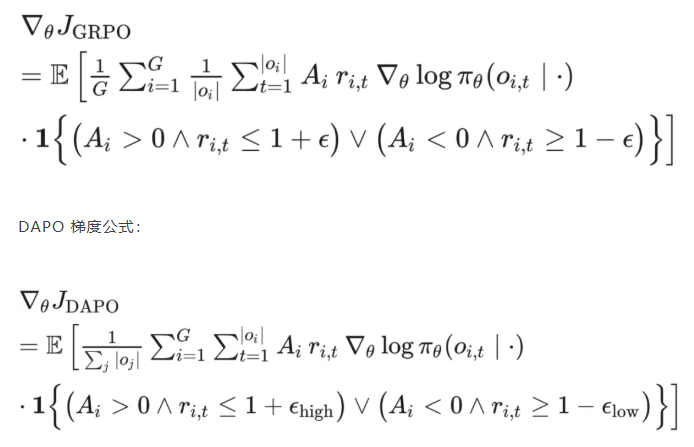
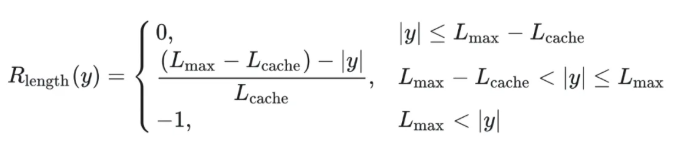







Comments NOTHING